先日Difyのロードマップが発表されました。
https://roadmap.dify.ai/roadmap
並列処理やファイルアップロードなど目玉機能もあるのですが、
個人的にRAGに注目していて、2024年末に『RAG2.0 pipeline orchestration』という機能追加が予定されているようで、
参照情報があったのでこちらで翻訳したものを掲載しております。
翻訳には生成AIを活用しています。
元記事は https://ragflow.io/blog/future-of-rag になります。
記事の要約
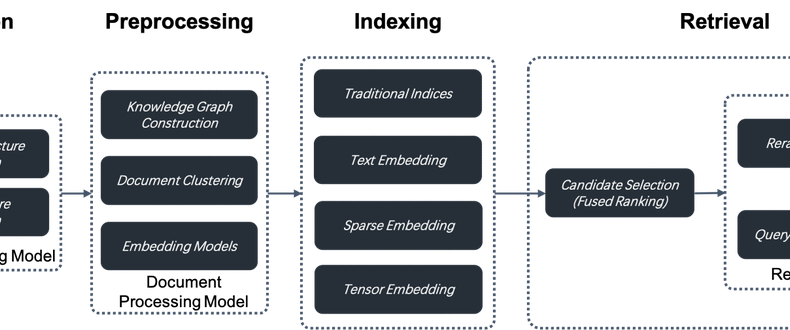
- RAG2.0は情報抽出、ドキュメント前処理、インデックス作成、検索という段階を統合した検索システム
- 全文検索、スパースベクター検索、密なベクター検索を組み合わせる
- Tensor検索は新しい検索方法、RAG2.0向けDBは全文検索とTensor検索を組み合わせることが有益
- まだまだ発展途上
RAGについて
検索技術はコンピュータサイエンスにおける主要な課題の一つであり、効果的に検索できる商業製品はほとんどありませんでした。大規模言語モデル(LLM)が登場する以前は、強力な検索機能は必須とは見なされておらず、ユーザー体験に直接貢献しなかったためです。しかし、LLMが人気を博するにつれて、エンタープライズ環境でLLMを活用するためには強力な内蔵検索システムが必要になりました。これをリトリーバル・オーグメンテッド・ジェネレーション(RAG)と呼びます。これは、LLMに最終的な回答生成のためにフィードする前に、ユーザーのクエリに最も関連性の高いコンテンツを内部の知識ベースから検索するというプロセスです。
LLMがユーザーのクエリに答えるシナリオを想像してみてください。RAGがない場合、LLMはトレーニングデータのみに依存しますが、RAGがある場合、LLMは教科書の中から答えを持っている可能性のある段落を検索することができ、まるでオープンブック試験のようになります。現代のLLMは、数百万トークンのコンテキストウィンドウを持ち、非常に長いユーザーのクエリを処理できるように進化しています。ここで疑問が生じます:LLMのコンテキストウィンドウが教科書全体を保持できるのなら、なぜ教科書の中で別途検索する必要があるのでしょうか?実際には、LLMのコンテキストウィンドウが大きくても、別途検索が重要である理由はいくつかあります。
- エンタープライズの文書は通常、複数のバージョンがあり、すべてをLLMに供給して回答を生成すると、矛盾した回答が生じる可能性があります。
- ほとんどのエンタープライズシナリオでは、コンテキストウィンドウに供給されるコンテンツに対して厳格なアクセス制御が必要です。
- LLMは、意味的に関連するが無関係なコンテンツによって気を散らされる傾向があります。
- 数百万の無関係なトークンを処理することは、強力なLLMを使ってもコストがかかり、時間がかかります。
RAGの急速な普及は、さまざまなLLMOpsツールによるもので、これらのツールは機能的なシステムを作成するために、迅速に次のコンポーネントを統合します。
ここまではこれまでのRAGの話です。ロングコンテキストを渡せばRAGは不要ではという意見もありますが、大量の不要な情報を渡すとその分コストもかかるので、コストを抑える意味でもRAGに有用性があると思われます。
RAGの仕組みと制限
この意味的類似性に基づくアプローチは、数年間一貫して維持されています。文書はチャンク(例えば、段落単位)に分割され、埋め込みモデルを通じて埋め込みに変換され、ベクターデータベースに保存されます。検索時には、クエリも埋め込みに変換され、データベースは最も関連性の高いチャンクを見つけます。これらは理論的には最も意味的に関連する情報を含んでいます。このプロセスでは、LLMOpsツールが通常次のようなタスクを処理します:
- 文書の解析と固定サイズのチャンクへの分割。
- オーケストレーションタスク:チャンクを埋め込みモデル(オンプレミスまたはSaaS)に送信すること、生成された埋め込みと対応するチャンクをベクターデータベースに転送すること、プロンプトテンプレートを使用してベクターデータベースからクエリ結果を組み立てること。
- ユーザーの対話コンテンツの生成と返却、顧客サービスプラットフォームなどのビジネスシステムとの対話の接続を含むビジネスロジックの統合。
このプロセスは実装が簡単ですが、単純な意味的類似性に基づく検索システムにはいくつかの制限があるため、検索結果はしばしば満足のいくものではありません。
- チャンク単位の操作として、埋め込みプロセスでは、エンティティ、関係、イベントなど、重みを増やす必要があるトークンを区別することが難しくなります。これにより、生成された埋め込み内の効果的な情報の密度が低くなり、リコールが悪化します。
- 埋め込みは正確な検索には不十分です。例えば、2024年3月の企業の財務計画に関するポートフォリオを尋ねるユーザーは、異なる期間のポートフォリオや、同じ期間のマーケティングまたは運用計画、さらには他の種類のデータを受け取る可能性があります。
- 検索結果は選択された埋め込みモデルに大きく依存します。汎用モデルは特定のドメインでパフォーマンスが劣ることがあります。
- 検索結果はデータのチャンク化方法に敏感です。しかし、このLLMOpsベースのシステムは文書のチャンク化において本質的にシンプルで粗雑であり、データの意味や構造が失われることにつながります。
- ユーザーの意図認識が不足しており、単に類似性検索手法を改善するだけでは曖昧なユーザークエリに対する回答を効果的に向上させることはできません。
- 異種情報源からの多段階推論を必要とする複雑なクエリ、例えばマルチホップの質問応答を処理できません。
したがって、このLLMOps中心のシステムはRAG 1.0と見なすことができます。オーケストレーションとエコシステムを特徴としているものの、効果においては不足しています。開発者はRAG 1.0を使用してプロトタイプシステムを迅速に構築できますが、実際のエンタープライズ環境での問題に取り組む際にはしばしば行き詰まります。したがって、RAGはさまざまな専門ドメインでの検索を促進するために、LLMと共に進化し続けなければなりません。最終的には、検索システムの目標は答えを見つけることであり、単に最も類似した結果を取得することではありません。これらの考慮に基づいて、我々はRAG 2.0のための以下の主要な機能とコンポーネントを提案します。
ここまでは既存のRAGですかね、DifyでもOpenAIのtext-embeddings-largeモデルを使って埋め込み、情報取得しています。さらなる精度向上が望まれる領域です。
RAG2.0の提案
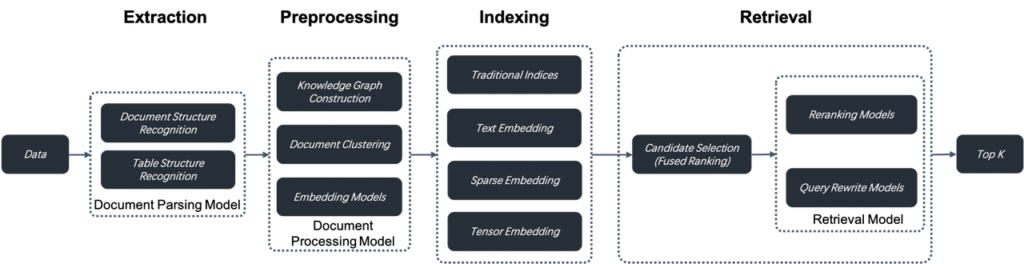
- RAG 2.0は、情報抽出、ドキュメント前処理、インデックス作成、検索という段階に分かれたエンドツーエンドの検索システムです。これらの段階は結合されており、統一されたAPIやデータ形式が欠如しているため、RAG 1.0用に設計されたLLMOpsツールを再利用してオーケストレーションすることはできません。また、循環依存性も存在します。例えば、マルチホップ質問応答やユーザーの意図認識に不可欠なクエリの書き換えは、反復的な検索と書き換えを含みます。ここでオーケストレーションを導入することは、必要ないだけでなく、検索やランキングの最適化に干渉する可能性があります。このことは、最近のAIオーケストレーションフレームワークであるLangChainに対する批判の一因でもあります。
- RAG 1.0の低リコールに対処するためには、ハイブリッド検索をサポートするより包括的で強力なデータベースが必要です。ベクター検索を超えて、全文検索やスパースベクター検索も含まれるべきです。さらに、ColBERTのような遅延インタラクションメカニズムをサポートするTensor検索も実装する必要があります。
全文検索は正確な検索に不可欠であり、明確な意図を持つクエリに対して期待される文書が返されないと非常にフラストレーションがたまります。さらに、一致したキーワードを表示することで、全文検索は検索結果の理由を理解する手助けをし、ランキング結果の説明可能性にも寄与します。したがって、ほとんどの状況において、RAGの検索オプションから全文検索を削除することは推奨されません。全文検索は多くの年にわたって存在していますが、実装は依然として容易ではありません。膨大なデータを扱う必要があるだけでなく、RAGのクエリは通常、いくつかのキーワードの組み合わせではなく完全な文であるため、Top-K Unionセマンティクスに基づく検索オプションを提供する必要があります。残念ながら、市場に出回っているBM25や全文検索をサポートすると主張するデータベースは、どちらの能力にも欠けています。これらは高性能な大量データ検索をサポートせず、効果的な検索を提供しないため、エンタープライズレベルの検索には適していません。
IBM Researchからの最近の発見は、全文検索、スパースベクター検索、および密なベクター検索を組み合わせることで、いくつかの質問応答データセットにおいて最先端の結果が得られることを示しています。これは、このような三方向検索機能をネイティブにサポートするデータベースの将来に対して有望な示唆を与えています。
Tensor検索は、ColBERTのような遅延インタラクションメカニズム向けに特別に設計された新しい検索方法です。要約すると、クロスエンコーダはクエリと文書間の複雑な相互作用を捉えることができ、通常のベクター検索よりもより正確なランキング結果を生成します。しかし、クエリと文書の両方のパッセージのエンコーディングタスクを「 juggling」する必要があるため、クロスエンコーダは通常、ランキングタスクにおいて非常に遅く、最終結果の再ランキングにのみ適しています。ColBERTのようなランキングモデルは、通常のベクター検索よりもはるかに少ない情報損失でより高い検索精度を達成します。これは、文書を表すために複数の埋め込みまたはテンソルを使用し、文書内の各トークンの類似性を計算するからです。また、文書のエンコーディングがインデックス作成段階でオフラインで行われるため、クロスエンコーダを上回ります。これにより、検索段階でのランキングにおいて実用的な選択肢となります。したがって、RAG 2.0向けに設計されたデータベースには、全文検索とTensor検索を組み合わせたハイブリッド検索機能を備えることが有益です。
- データベースはRAG 2.0においてクエリと検索のみをカバーしています。グローバルな視点から見ると、RAGパイプラインの各段階を最適化することが重要です。これには以下が含まれます:
ユーザーデータをチャンク化するためには、別のデータ抽出とクレンジングのモジュールが必要です。さまざまな認識モデルのコレクションに依存して、テーブルやイラストと混ざったテキストなど、さまざまな複雑な文書構造を認識し、検索結果に応じてチャンクサイズを反復的に調整します。データ抽出とクレンジングプロセスは、現代のデータスタックにおけるETLに似ていますが、はるかに複雑です。ETLは本質的にSQLベースの決定論的システムであるのに対し、このプロセスは文書構造認識モデルを中心に構築された非標準システムです。
抽出されたデータはインデックス作成のためにデータベースに送信される前に、知識グラフの構築、文書のクラスタリング、ドメイン特化型の埋め込みなど、いくつかの前処理手続きに従う必要があります。これらの手続きは、抽出されたデータを複数の方法で前処理することで、検索結果が必要な回答を保持することを保証します。これは、マルチホップ質問応答、曖昧なユーザーの意図、ドメイン特化型の問い合わせなど、複雑なクエリの問題に対処するために重要です。
抽出されたデータはインデックス作成のためにデータベースに送信される前に、知識グラフの構築、文書のクラスタリング、ドメイン特化型の埋め込みなど、いくつかの前処理手続きに従う必要があります。これらの手続きは、抽出されたデータを複数の方法で前処理することで、検索結果が必要な回答を保持することを保証します。これは、マルチホップ質問応答、曖昧なユーザーの意図、ドメイン特化型の問い合わせなど、複雑なクエリの問題に対処するために重要です。
RAG 2.0の各段階は基本的にモデルを中心に構築されています。これらはデータベースと連携して、最終回答の効果を保証します。
RAG 2.0はデータベースとAIモデルを中心に構築されており、継続的な反復のためのプラットフォームが必要です。これにより、私たちはRAGFlowを開発し、オープンソース化しました。既存のRAG 1.0コンポーネントを再利用するのではなく、RAGFlowはパイプラインの視点からLLM検索システムの根本的な課題に取り組んでいます。オープンソースリリースから3ヶ月足らずで1万のGitHubスターを獲得し、新たな始まりを示しました。しかし、RAGFlowはまだ初期段階にあり、そのすべての部分はさらなる進化が必要です。
RAG 2.0はエンタープライズシナリオにおけるLLMアプリケーションに大きな影響を与えるでしょう。私たちはAIの原動力としての未来に期待を寄せています。もしあなたも興味があるなら、私たちの作業をフォローしていただけると嬉しいです。https://github.com/infiniflow/ragflow












この記事へのコメントはありません。