
生成AIを使って社内文書などの外部情報を参照する技術はRAGと呼ばれます。
RAG・・検索拡張生成
RAGは現在進行で発展中でいろんな手法があるので、生成AIも活用しつつそれぞれの内容やメリットデメリットを調べてみました。
VectorRAG
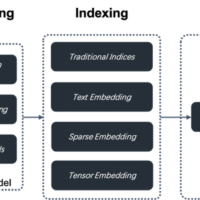
Difyでも扱われている一般的なベクトル検索になります。キーワードに関係する文書を検索するので、関連性の把握が難しい専門用語だと精度が落ちるようです。
特徴:
- 文書をパラグラフレベルでチャンク化し、ベクトル検索を使用して関連情報を取得
メリット:
- 実装が比較的簡単
- 大規模なデータセットに対して効率的
デメリット:
GraphRAG
Difyでは今の所実装できませんが、知識グラフを使って情報抽出する方法もあります。
こちらはLangChainと、Neo4j(グラフデータベース)があれば実装できそうです。
(グラフデータベースについてまたリサーチせねば)
特徴:
- 知識グラフを使用して情報を構造化し、関連性の高い情報を抽出
メリット:
- 複雑な関係性を持つ情報の取り扱いに優れている
- 文脈を考慮した情報抽出が可能
デメリット:
- 知識グラフの構築と維持にコストがかかる
- 新しい情報の追加が難しい場合がある
HybridRAG
VectorRAGとGraphRAGを統合したアプローチ
メリット:
デメリット:
- 実装の複雑さが増す
- 計算コストが高くなる可能性がある
Self-Route
Difyでも実装可能。RAGで関連文書を抽出した後に、この内容で正しく回答できるのかを言語モデルが考える
ユーザーの質問と抽出した文章を同時にプロンプトに入れれば実現できる。
正しく回答できないと判断した場合は、文章を抽出するのではなく、丸々全文をプロンプトに埋め込み回答する。
RAGで回答できない場合に全部の文書を使う。
Difyで実施する場合はLLM->IF/ELSE->テンプレートブロックなどを使い、全文を出力する
- 特徴: Self-Routeは、情報取得と生成のプロセスを自己指導型で行う手法で、モデル自身が関連情報を探索し、選択して生成に活用します。
- メリット:
- 自律的な情報探索が可能で、特定のドメインに特化した情報生成ができる。
- ユーザーの介入が少なくても動作する。
- デメリット:
- 自己指導型のため、誤った情報を取得するリスクがある。
- 訓練データに依存するため、ドメイン外の情報に対して効果が薄い場合がある。
他の手法
他にもDR-RAG (Dynamic Relavance RAG)、Adaptive-RAG などの手法もあり、まだ論文段階のものもあるようです。
RAGの手法をまとめてみて
文書によってどの手法が最適なのかというのは異なリ、文書ごとに手法を変えて精度確認するというのもコストがかかり現実的ではないと思われます。
いくつかの手法を用意しておいて、自動的にどの手法が最適なのかを判断してくれると理想的なので、Difyにその機能が追加されたらいいなと期待しながらソースコードなど読んでいこうと思います。












この記事へのコメントはありません。